
Quand une équipe démarre Kubernetes en entreprise, le véritable enjeu n’est pas de déployer un pod.
Le véritable enjeu, c’est de poser un cadre clair dès le premier namespace.
Un namespace laissé “à nu” devient rapidement une zone grise. Pas de limites de ressources, pas de garde-fou de capacité, des permissions accordées trop largement pour aller plus vite. Et quelques semaines plus tard, on se retrouve à expliquer un incident qui aurait pu être évité avec une base propre dès le départ.
Dans cet article, nous allons poser une baseline concrète pour un namespace production sur un cluster local kind.
L’objectif est simple : mettre en place des limites par défaut, un quota global et un accès minimal en lecture via RBAC, puis vérifier que tout fonctionne réellement.
L’idée n’est pas seulement d’appliquer des manifestes, mais d’observer le comportement du cluster.
Cadre de décision
Avant d’exécuter la moindre commande, gardons en tête le cadre suivant :
- l’objectif est de valider un comportement précis de Kubernetes ;
- la preuve attendue est observable via
get,describe,eventsou un message d’erreur explicite ; - ce scénario est un laboratoire technique, à rejouer en préproduction avant toute utilisation réelle.
1. Pourquoi cette baseline est importante
Sans règles de base, on retrouve souvent les mêmes problèmes :
- des workloads sans requests ni limits ;
- un namespace qui consomme toutes les ressources disponibles ;
- des permissions trop larges accordées par facilité ;
- des post-mortem compliqués parce que rien n’était contraint.
Une baseline simple ne règle pas tout, mais elle crée un cadre sain dès le départ.
2. Prérequis
Avant de commencer, assurez-vous d’avoir les outils suivants :
- Docker
- kubectl
- kind
Vous pouvez vérifier leurs versions :
docker version
kubectl version
kind version
3. Créer le namespace et définir les limites
Nous allons créer un namespace production, puis y appliquer deux mécanismes essentiels :
Un LimitRange pour définir des valeurs par défaut au niveau des conteneurs.
Un ResourceQuota pour limiter la capacité globale du namespace.
Création du namespace :
kubectl create namespace production
Création du fichier production-baseline.yaml :
apiVersion: v1
kind: LimitRange
metadata:
name: defaults
namespace: production
spec:
limits:
- default:
cpu: "200m"
memory: "256Mi"
defaultRequest:
cpu: "100m"
memory: "128Mi"
type: Container
---
apiVersion: v1
kind: ResourceQuota
metadata:
name: production-quota
namespace: production
spec:
hard:
pods: "5"
requests.cpu: "1"
requests.memory: "1Gi"
limits.cpu: "2"
limits.memory: "2Gi"
Application du manifeste :
kubectl apply -f production-baseline.yaml
kubectl -n production describe resourcequota production-quota
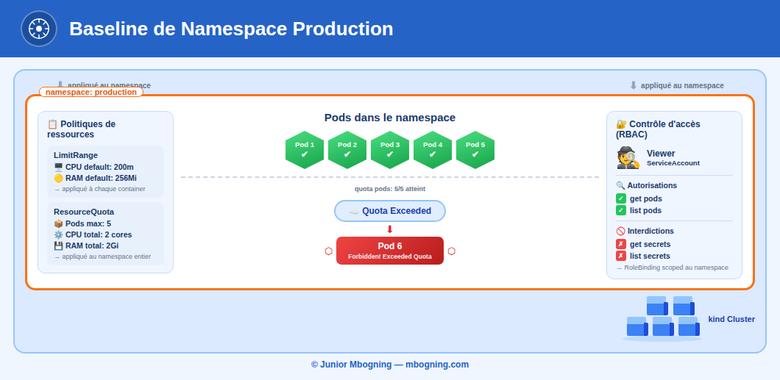
À ce stade, le namespace est encadré. Aucun pod ne pourra dépasser ces contraintes globales.
4. Vérifier le comportement du quota
Nous allons maintenant tester concrètement la limite fixée à cinq pods.
for i in 1 2 3 4 5; do
kubectl -n production run app-$i --image=busybox:1.36 --restart=Never --command -- sh -c 'sleep 3600'
done
kubectl -n production wait --for=condition=Ready pod/app-1 pod/app-2 pod/app-3 pod/app-4 pod/app-5 --timeout=240s
Puis tentons de créer un sixième pod :
kubectl -n production run app-6 --image=busybox:1.36 --restart=Never --command -- sh -c 'sleep 3600'
Résultat attendu : un refus avec un message indiquant que le quota est dépassé.
C’est précisément ce que l’on veut observer. Le cluster applique la règle et protège le namespace.
5. Ajouter un RBAC minimal en lecture
Nous allons maintenant créer un service account viewer capable uniquement de lire les pods du namespace production.
Création du service account :
kubectl -n production create serviceaccount viewer
Création du fichier production-rbac.yaml :
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: pod-reader
namespace: production
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: pod-reader-binding
namespace: production
subjects:
- kind: ServiceAccount
name: viewer
namespace: production
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: pod-reader
Application :
kubectl apply -f production-rbac.yaml
6. Vérifier les permissions
Nous allons tester explicitement les droits du service account.
kubectl auth can-i list pods -n production --as=system:serviceaccount:production:viewer
kubectl auth can-i create pods -n production --as=system:serviceaccount:production:viewer
kubectl auth can-i get secrets -n production --as=system:serviceaccount:production:viewer
Puis tester directement une action :
kubectl -n production --as=system:serviceaccount:production:viewer get pods
kubectl -n production --as=system:serviceaccount:production:viewer create configmap viewer-test --from-literal=check=true
Le comportement attendu est le suivant :
- la lecture des pods est autorisée ;
- la création de pods est refusée ;
- l’accès aux secrets est refusé ;
- la création d’une ressource est bloquée.
Cela confirme que le principe du moindre privilège est respecté.
7. Résultats observés
Ce scénario a été validé sur un environnement Linux amd64 avec les versions stables suivantes :
Docker Engine 29.2.1kubectl v1.35.1kind v0.31.0- image de nœud kind
kindest/node:v1.35.0
Les résultats observés sont conformes aux attentes :
- cluster créé correctement ;
- nœud en état
Ready; LimitRangeetResourceQuotaappliqués ;- cinq pods créés et en état
Running; - sixième pod refusé avec dépassement de quota ;
- service account et règles RBAC fonctionnels ;
- permissions limitées conformément à la définition.
Conclusion
Cette baseline est volontairement simple, mais elle pose des fondations solides. Elle force des limites par défaut dès la création des workloads, encadre la consommation globale des ressources et applique le principe du moindre privilège côté accès.
Autrement dit, elle transforme un namespace vide en un espace gouverné, prévisible et maîtrisé.
En production, ce type de cadre réduit significativement les incidents liés à la saturation des ressources, aux déploiements mal configurés ou aux permissions trop larges accordées par facilité. Ce sont souvent ces “petits oublis” du début qui deviennent des problèmes majeurs quelques semaines plus tard.